SQL: Elementos con un número indeterminado de columnas
En muchas ocasiones tenemos una tabla a la que queremos añadir un número indeterminado de atributosa modo de columnas. Sin embargo, esto plantea un problema, ya que el número de columnas puede variar de forma dinámica. Por ejemplo, tenemos una tabla “libro” que, en principio, tiene su título, su autor, etc, pero de pronto queremos añadirle un ISBN, o una keyword. ¿Cómo hacemos eso?
En este artículo se explican las posibles soluciones a este problema.

Abordando el problema
La mayor dificultad del problema radica en que estamos tratando de hacer uso de elementos estáticos como dinámicos. En SQL, las columnas son estáticas, no deberían alterarse a menudo (si es nunca, mejor). Sin embargo las filas sí son dinámicas y van a cambiar constantemente. Así que la solución a nuestro problema es tan simple como transformar las columnas en filas.
De esta manera, lo que antes teníamos como una única tabla, ahora se transformará en 3. Evidentemente, esto va a tener un coste en complejidad y es probable que haga nuestra base de datos más lenta, aunque es probable que no sea así, como veremos más adelante.
Para este artículo, utilizaré como ejemplo un “nodo”, que contiene los campos “id” y “title”, además de un conjunto de atributos.
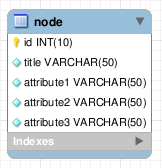

La técnica a utilizar consiste en dejar en la tabla principal sólo la información obligatoria o necesaria de nuestros elementos. En nuestro ejemplo, eso reduce la tabla “nodo” a dos columnas: “id” y “title”.
Además, necesitaremos una tabla auxiliar con la definición de los atributos. Esta tabla contendrá 3 columnas: El “id” propio de la tabla, el “id” del nodo al que pertenece y el nombre del atributo; en este caso, si quisiéramos hacer una base de datos equivalente a la mostrada anteriormente, usaríamos 3 filas en esta tabla: “attribute1”, “attribute2” y “attribute3”. Le he añadido un campo “type” con el fin de complicarlo todo lo posible: algunos atributos tendrán distintos tipos. Por ejemplo: el “attribute1” va a ser un entero, “attribute2” una cadena.
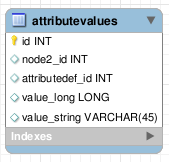
Una vez hemos definido estas dos tablas, requerimos de otra más con los valores de los atributos. Esta tabla, como veremos a continuación, va a ser la más difícil de gestionar, ya que existen distintas formas de abordarla. En principio nos vamos a quedar con los campos necesarios de la tabla: “id” para la clave primaria (aunque no sería esencialmente necesario, ya que puede obtenerse la clave primaria con los dos campos siguientes), el “id” del nodo al que pertenece y el “id” del atributo al que pertenece.
Esta tabla de valores contendrá también el valor de los atributos. Si tenemos suerte y queremos que todos los nodos de la tabla tengan el mismo tipo, basta con añadir una columna más “value” de ese tipo a esta tabla de valores y dejar de leer aquí. Sin embargo, es muy probable que esto no sea así y necesitemos diferentes tipos para poder solucionar nuestro problema. Existen 3 maneras de abordar este problema: jerarquías de tablas, una única tabla de valores y polimorfismo.
Una única tabla de valores
La manera más sencilla es crear una columna de cada tipo en nuestra tabla de valores. De esta manera, elegiremos una columna u otra dependiendo del valor de la columna “type” de la tabla de definición de atributos.
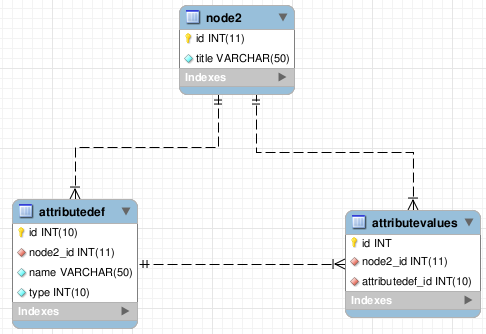
En el ejemplo, podremos crear dos columnas, una de enteros y otra de cadenas, de manera que el “attribute1” lea los enteros y el “attribute2”, las cadenas.
Esta solución es bastante sencilla de llevar a cabo, no requiere tablas extra, y el espacio requerido por cada fila es constante. El problema es que es muy probable que se van a tener muchos campos nulos (a menudo más que campos con contenido) y que no podemos obligar a tener valor en alguno de ellos, salvo mediante código. Ésta puede ser las solución cuando sólo hay uno o dos tipos de valores y sabemos a ciencia cierta que nunca va a haber más. Por experiencia sé que cuando estamos seguros de que no puede haber más de 2 de algo, en seguida aparece un tercero, un cuarto, … Por lo que no recomiendo el uso de esta técnica.
Polimorfismo
Otra posible solución es utilizar un tipo de valor que pueda englobarlos a todos, como una cadena, por ejemplo. Se pueden utilizar distintas codificaciones para los distintos tipos, de manera que podamos “hacer un cast” a nuestro tipo original.
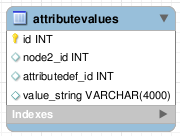
En el ejemplo, crearíamos una única columna “value” de tipo cadena, y convertiríamos los enteros a cadena. Dependiendo del tipo de la tabla de definición de atributos, durante la recuperación de datos transformaremos el valor a entero o no.
Esta técnica reduce considerablemente el espacio necesario para almacenar los datos, ya que sólo tenemos una columna que nunca va a ser nula, y cada fila ocupa un tamaño fijo. El problema es qué ocurre si necesitamos un tipo con un tamaño mucho más grande, como pueda ser un BLOB o, simplemente, cuando necesitamos una cadena de 4K mientras que el resto de atributos sólo va a llegar a unos pocos caracteres.
Además, perdemos velocidad, ya que estaremos comparando con el más lento de los mecanismos, y perderemos características como los comparadores distintos del “igual” y el “distinto de”.
Jerarquía de tablas
Otra solución es crear una tabla por cada tipo, de manera que, gracias a lo que indique la columna “type” en la tabla de definición de atributos, sepamos a qué tabla tenemos que hacer referencia.
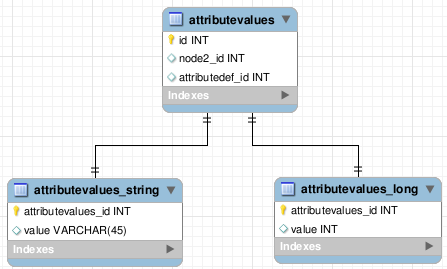
Ésta es la solución más económica en cuanto a espacio, nos permite aprovechar las ventajas de cada tipo, pero tiene el inconveniente de que, a menudo, habrá que filtrar cada tipo de forma individual. La buena noticia es que buscaremos entre menos información, lo que lo hará más rápido. La gestión de este tipo de soluciones suele ser bastante más compleja que el resto.
Esta solución puede ser la mejor de todas si tenemos muchos tipos cambiantes o prevemos que en el futuro va a aumentar el número de tipos.
Listas de valores
¿Qué ocurre cuando el valor de un atributo puede ser una lista de valores? Por ejemplo, si estamos almacenando libros, podría darse el caso de que haya varios autores.
Entonces basta con añadir una columna más a la tabla de valores (a la principal), que indique el número de orden del valor (si queremos que siempre nos los muestren en el mismo orden claro), y el problema está solucionado.