Colas de mensajes: RabbitMQ
Cuando se desarrolla una aplicación y ésta comienza a crecer, a menudo necesitamos interconectar distintos componentes. En estos casos se utiliza un middleware que nos permita comunicar las distintas piezas.
Una opción es usar una cola de mensajes. No es el mecanismo más rápido, pero probablemente sí el más sencillo, y permite realizar acciones de forma asíncrona.
Y un gestor de colas de mensajes sencillo, robusto y muy utilizado es RabbitMQ.

Instalando RabbitMQ
Esta aplicación Erlang es sencilla de instalar en Linux:
| |
Y tendremos la aplicación funcionando, escuchando en el puerto 5672.
Es interesante instalar el plugin de gestión para poder ver qué está pasando ahí dentro. Para ello basta con hacer:
| |
Y automáticamente lo tendremos escuchando en https://localhost:15672/
Lo básico de RabbitMQ
Hay algunos conceptos que hay que tener claros de RabbitMQ:
Exchange Es el punto de entrada de un mensaje. Pueden ser Direct, si entregan un mensaje en una cola, Fanout si se entregan copias del mensaje a todas las colas o Topic si se entregan copias del mensaje sólo a algunas colas.
Queue Es el punto de lectura de un mensaje. Pueden ser durable o persistentes, si almacenan los mensajes para sobrevivir a un reinicio de RabbitMQ_. También pueden ser exclusivas, si sólo un consumidor puede estar conectado a la vez.
Bindings Son reglas que indican cómo llegar de un Exchange a las Queue asociadas.
Routing key Filtro asociado a un Binging que permite seleccionar sólo algunos mensajes para dicho binding.
Producer o Productor Programa que escribe en un Exchange
Consumer o Consumidor Programa que escucha en una Queue
AMQP Protocolo de comunicaciones utilizado por RabbitMQ. Lo usa tanto el Productor como el Consumidor.
Virtual host o vhost Un entorno aislado, con sus propios grupos de usuarios, exchanges, queues, …
mnesia La base de datos interna de RabbitMQ
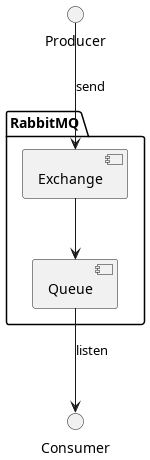
Una vez dicho esto, podemos describir el flujo básico de RabbitMQ:
Claro, que esto puede evolucionar a entornos mucho más complejos:
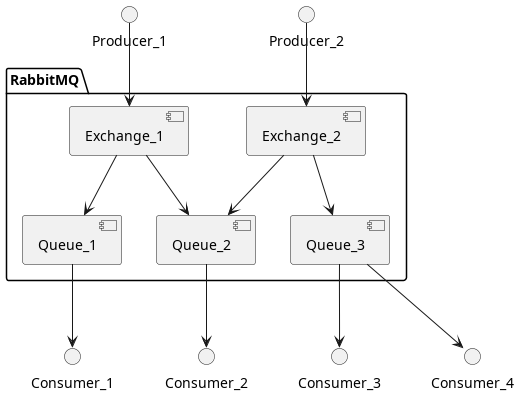
En este entorno, y asumiendo que los Exchange están en modo Topic (es decir, que un mensaje llega a todas las colas):
Consumer_1recibe todo lo que produzcaProducer_1, pasando porQueue_1. Este tipo de escenario es igual que el básico.Consumer_2recibe todo lo que produzca tantoProducer_1comoProducer_2, pasando porQueue_2. Útil para procesar eventos que se producen en distintos lugares pero tienen un destino común. Ejemplo: guardar logs de distintas máquinas en base de datos.Consumer_3yConsumer_4se repartirán lo producido porProducer_2, pasando porQueue_3. Útil cuando la carga producida es muy alta y se requieren muchos recursos para consimir cada mensaje. Ejemplo: Renderización de vídeo 3D.
Puertos y valores por defecto
Si no cambiamos nada, RabbitMQ escucha en el puerto 5672, y la interfaz de administración en el 15672.
Se crea un usuario guest/guest que nos permite acceder a ambas.
RabbitMQ consume mucha memoria. Recomiendo utilizar servidores dedicados, para que no se haga con toda y tengamos problemas.
Algunas tareas de administración
Crear un vhost
Con el fin de aislar un entorno, podemos crear un vhost. Nada más sencillo:
| |
Crear un usuario
Ahora podemos crear un usuario
| |
Y podemos asociarlo al vhost:
| |
Asignar permisos
Si queremos poder utilizar este usuario para entrar en la interfaz de administracción, necesitamos darle permisos de management y monitoring:
| |
Por tanto, los mensajes se escriben en un Exchange pero se leen de una Queue. Para llegar de un Exchange a una Queue se utilizan los Routes.
Crear un cluster
Una de las tareas típicas es crear un cluster de RabbitMQ. Esto nos permite mejorar la disponibilidad del sistema, ya que si uno de nuestros servidores cae, el otro seguirá atendiendo peticiones.
Esta tarea es algo más compleja. Supongamos que tenemos dos nodos: rabbit1 y rabbit2. Vamos a añadir Rabbit2, dejando Rabbit1 como maestro inicial. Lo primero que podemos hacer es ver el estado actual del sistema:
| |
Para crear un cluster, tenemos que parar uno de los RabbitMQ, pero debemos hacerlo con órdenes especiales:
| |
A continuación lo añadimos al cluster:
| |
Y volvemos a arrancar:
| |
Ahora podemos comprobar que todo fue bien:
| |
Aunque también podemos verlo desde la herramienta de administración (mucho más molona XD)
Es IMPORTANTE que todos los nodos de un cluster tengan la misma versión de RabbitMQ o podríamos tener problemas.
Si se va a gestionar un cluster, recomiendo encarecidamente leerse toda la documentación de RabbitMQ sobre clusters. Es poco y muy conveniente. Además, es bueno tenerlo siempre a mano.
Una vez creado el cluster se puede utilizar una VIp (Virtual IP), de manera que nos respondan ambos indistintamente. Si uno cae, la VIp se puede cambiar mediante Keepalive y, si preparamos nuestra aplicación para hacer reintentos, no se verá afectada por la caída.
En la interfaz de administración podemos ver cómo los mensajes estarán replicados en ambos nodos, el estado de los mismos, etc.
Programando
Para programar contra un RabbitMQ recomiendo usar una de las librerías AMQP. Hay otras opciones de más alto nivel. Por ejemplo, en Python está Kombu, que se abstrae de la cola de mensajes a usar, o incluso Celery, que permite usar una cola de mensajes para la gestión de tareas distribuidas.
Veamos unos ejemplillos sencillos. Recordad que hay muchas opciones y se pueden configurar bastantes historias, pero voy a ir a lo básico:
Python
Utilizaré la librería Pika (tomado de la propia documentación de la librería):
El consumidor:
| |
Y el productor:
| |
Java
Usando la rabbitmq-java-client, el consumidor:
| |
y el productor:
| |
Debo admitir que no los he probado… Así que si alguien encuentra algún fallo, que me lo diga XD
Conclusión
RabbitMQ es un canal de comunicaciones. Quizá no sea muy rápido, ya que no deja de ser un man-in-the-middle, pero permite integrarse fácilmente con cualquier sistema existente.
Además, como no fuerza ningún formato de mensaje, resulta muy sencillo crear conectores que permitan publicar/consumir mensajes e integrar distintos escenarios. Y en las últimas versiones han añadido soporte para mensajes prioritarios, lo que puede dar mucho juego para enviar mensajes de control.
De todas maneras, RabbitMQ es sólo un sistema de colas de mensajes, pero hay otros. También está Apache ActiveMQ, Apache Kafka, Apache Qpid, ZeroMQ, HornetQ, Sparrow, Starling, Amazon SQS, Beanstalkd, …