Cómo puede cambiar los despliegues Docker
Llevo ya bastante tiempo pensando cómo desplegar correctamente una aplicación. La idea es ser capaz de desplegar en un sistema distribuido sin DoS .
El principal problema reside en cómo sincronizar todas las máquinas para realizar el cambio en el menor tiempo posible, así como en evitar puntos de fallo y admitir rollback. Casi na.
Sin embargo, Docker facilita todo esto. Aquí explico cómo se me ha ocurrido, aunque no es nada que probablemente no se os haya pasado por la cabeza a vosotros también.
Y mis agradecimientos al grupo Agile-CR, que me ayudaron a poner en orden alguna de estas ideas.

Problemas de despliegue
Existen numerosos problemas durante el despliegue:
- ¿Cómo llevar el software hasta todas las máquinas de un cluster?
- ¿Cómo configurarlas?
- ¿Cómo reemplazar la versión antigua en el menor plazo de tiempo posible?
- ¿Cuándo sincronizar la Base de Datos?
- ¿Es posible que la aplicación funcione durante un tiempo con una configuración errónea?
Por supuesto, estamos hablando de sistemas con una alta disponibilidad, cercana al 99.99%. Esto incluye, principalmente, servicios internos y servicios web.
El esquema, por tanto, tendrá esta pinta:
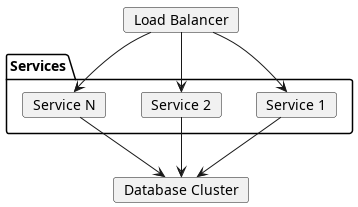
Resulta sencillo ver que:
- Si desplegamos primero la base de datos, el sistema estará inconsistente hasta que se despliegue el resto.
- Si desplegamos primero la configuración, pasará lo mismo.
- Si desplegamos primero el software, puede estar mal configurado o no ser acorde con la base de datos.
Luego el problema tiene difícil solución.
Herramientas como Puppet, Chef, Salt o Ansible pueden ayudar, pero también pueden ser foco de problemas, ya que suelen ser declarativas. Además, es posible que necesitemos realizar operaciones en distintas máquinas, como evitar que el balanceador de carga sirva la máquina que estamos alterando o lanzar los cambios de base de datos.
Desplegando la base de datos
Quizá el punto de fallo más crítico es la base de datos. La única manera posible de evitar problemas durante el despliegue es dividir los cambios en dos.
Por una parte, todos los create, add column, insert, etc. Estas operaciones son inócuas y no deberían afectar al despliegue actual, más allá de una pequeña reducción temporal de rendimiento.
Por otra parte, los drop, delete, alter, etc. Que son operaciones que sí pueden tener repercusiones.
Los alter que modifican el nombre de una columna deberían estar prohibidos completamente, ya que se ejecuten donde se ejecuten dejarán el sistema inestable durante un tiempo.
Con estas premisas, es fácil ver que podemos ejecutar el primer grupo antes de instalar la nueva versión del software y el segundo grupo después de la instalación de éste.
Y con esto, el despliegue de nuestra base de datos es seguro.
Desplegando la aplicación y la configuración
Con la aplicación y la configuración no ocurre lo mismo. No importa qué se despliegue antes, afectará al funcionamiento.
Una opción es centralizar la configuración. Básicamente se deja la configuración en una base de datos y se accede a ella directamente o mediante un servicio intermedio (yo recomendaría esto último).
Pero hay cierta configuración que no puede moverse a este nuevo sistema: La configuración para conectarse a él. Sin embargo, ésta es una configuración que no cambiará a menudo y que, probablemente, sea igual en todos los servicios de un mismo tipo.
Soluciones al despliegue
Duplicando el sistema
Una posible solución es duplicar el sistema. Se duplican las máquinas y se instala la nueva aplicación en las máquinas nuevas. Luego se cambia el Load balancer y todo solucionado.
El problema de esta solución es el coste. Si albergamos nuestro propio hardware, necesitamos duplicar el número de máquinas para una acción que se realiza en pocos minutos.
Sin embargo, también tiene ventajas adicionales:
- El cambio se realiza en todas las máquinas al mismo tiempo.
- Se podría probar la nueva versión de la aplicación en distintas máquinas, comprobando que tiene el mismo funcionamiento que la versión anterior (al menos).
- Permite A/B Testing.
- Permite hacer rollback de forma sencilla.
Dockers
Y aquí es cuando viene Docker al rescate. Si no sabéis qué es, podéis ver mi artículo anterior sobre Docker.
Docker permite ver la aplicación y su configuración como una caja negra, permitiéndonos desplegar más de un servicio idéntico en la misma máquina.
Por lo tanto, podríamos mantener desplegadas las dos versiones de nuestra aplicación al mismo tiempo, quizá en puertos diferentes, y servir ambas. Durante un despliegue, se mira cuál es la activa y se sustituye la inactiva. A continuación se cambia el Load Balancer y todo queda resuelto en milésimas de segundo.
Docker nos permite, por tanto, duplicar el sistema utilizando el mismo hardware. La carga adicional será tan pequeña como permita nuestro contenedor de aplicaciones, si es que estamos usando JBoss o similar. Seguramente sea una carga en RAM, pero poco en CPU.
De esta forma ahorramos los costes y obtenemos todas las ventajas del sistema duplicado y algunas adicionales:
- la gestión de todos nuestros servicios se puede realizar de forma homogénea, es decir, que podemos desplegar cualquier servicio de la misma manera.
- Podemos mantener desplegadas varias versiones distintas para permitirnos hacer rollback o pruebas del conjunto, con un coste de un Load Balancer.
- Se pueden guardar las versiones como un bloque, usando los Docker Repositories. Esto también facilitará la forma de hacer llegar las imágenes a las máquinas donde se van a desplegar.
Por si esto fuera poco, Docker guarda información en los containers sobre los puertos que expone y los puntos de montaje, lo que puede facilitar la gestión de alertas (al menos a nievel básico).
Docker vs Puppet, Chef, Salt, Ansible, …
Seguramente penséis que Docker es mejor que los sistemas típicos de orquestación, como Puppet, Chef, Salt o Ansible. Sin embargo, son herramientas diferentes que sirven para objetivos diferentes.
Con este nuevo esquema de despliegues, podría usarse cualquiera de estos sistemas de orquestación para instalar la nueva aplicación en las máquinas, y planificar el momento en que se hará el cambio en el load balancer. Así, Docker y los sistemas de orquestación trabajan juntos.
También son útiles para cambiar la configuración a nivel global o configurar sistemas de monitorización y alertado.
Como vemos, son herramientas complementarias, no competencia.
Conclusión
Docker es un nuevo paradigma que ha llegado para quedarse, a pesar de estar basado en los “Linux Containers”, una tecnología que un amigo ya usaba allá por el 2004.