Kubernetes (1): conceptos básicos
Hoy en día toda web escalable es un sistema distribuido. Aunque se suele comenzar con un monolito, poco a poco se ve la necesidad de dividirlo en piezas más pequeñas o arquitecturas SOA o bien directamente a microservicios. En cualquier caso, los mecanismos de despliegue tradicionales dejan de ser eficaces. Y ahí surgen soluciones como Kubernetes y docker-swarm.
Un poco de historia
Hoy en día es dificil disfrutar de un problema que otros no hayan tenido antes. Y así pasó en las grandes empresas como Google, Amazon, Facebook, …
Todos ellos tenían sus soluciones de despliegue, unas mejores y otras peores. Pero fue Google quien construyó Borg. Borg era el motor de despliegue de uso interno.
Poco a poco el equipo de trabajo dejó de ser el mismo: entra sangre nueva y se va gente a otras empresas. Esta gente llega a una empresa nueva y ve la necesidad de mejorar el sistema de despliegue y… ¿En qué fijarse? Pues en lo que conoce: Borg. Hasta que un grupo de estos ex-empleados decide comenzar un proyecto abierto y libre: nace kubernetes.
El nombre “kubernetes”
“Kubernetes” hace referencia al timonel o el patrón de un barco en Esperanto. De ahí el logo, que recuerda a un timón.
A menudo se abrevia como “K8s”, que es como decir: “una K, 8 letras más y una
s”, pero nunca se pronuncia de esta manera. En inglés suena más bien como
cubirnitis o quiubirnities.
Mucho más que un sistema de despliegue
Pero no es sólo un sistema de despliegue, como puede pensarse de Ansible, Puppet o Chef. Kubernetes incluye sistemas de monitorización, escalado y auto-corrección. Es decir: sus funciones se extienden más allá del despliegue hasta gestionar los recursos durante la ejecución.
Cómo funciona
Kubernetes es, en sí mismo, un sistema distribuido. Las aplicaciones se dividen en dos grupos: el plano de control y el de nodo.

En el plano de control podemos encontrar:
- kube-apiserver, encargada de las comunicaciones. Todo pasa por ella, ya que gestiona los permisos, entre otras cosas.
- kube-scheduler, o planificador, asegurándose de que los recursos se distribuyen de acuerdo a las especificaciones.
- kube-control-manager, para tareas administrativas como gestión de nodos, de trabajos, endpoints, …
- etcd, que es la base de datos donde se guarda todo.
A nivel de nodo podemos encontrar:
- kubelet, que es un agente que debe ejecutarse en todos y cada uno de los nodos para permitir la gestión local de acuerdo a lo que diga el scheduler.
- kube-proxy, que es otro agente que vive también en todos los nodos para realizar tareas de red.
- container runtime, para ejecutar contenedores, como docker, containerd o CRI-O, o cualquier cosa que implemente la interfaz.
Luego también hay algunos addons muy comunes, como:
- DNS, sin el que no se puede trabajar, ya que los Pods no se verían entre sí.
- Web UI o dashboard, que permite la gestión desde el navegador.
Simplificando
Evidentemente, desplegar todo esto es un dolor. No ya por la cantidad de servicios y configuraciones, sino por la seguridad: cada servicio tiene sus claves privadas y debe compartir las públicas con aquellos que se comunican con ellos. Kelsey Hightower explica cómo hacerlo de forma manual en el Kubernetes the hard way, y casi todo el rato estás generando claves y compartiéndolas entre servicios.
Pero hay alternativas más sencillas:
- kind, que te instala un cluster kubernetes en un docker. Es ligerito para ser un kubernetes y fácil de manejar. Es el que suelo utilizar yo. Puede consumir unos 500Mb de RAM.
- minikube, que utiliza una máquina virtual tipo virtualbox. Require un consumo de recursos casi fijo con un mínimo de 2Gb de RAM.
Como digo, recomiendo kind, con lo que crear un cluster de kubernetes local puede ser tan sencillo como:
kind create cluster
Y en unos 20 segundos tendrás tu cluster listo para usar.
Herramientas básicas
La herramienta básica es kubectl, pronunciado quiubcontrol o quiubcitiel.
Necesita configuración en un archivo llamado kubeconfig, que habitualmente se
encuentra en ~/.kube/config y que si hemos usado kind ya estará creado y
listo para usar.
Recursos
Bueno… ahora sí… comencemos con kubernetes.
Antes hemos visto los servicios internos de Kubernetes, ahora veremos los recursos lógicos. Es decir: veremos cómo crear cosas dentro de kubernetes.
Todos los recursos se pueden mapear a formato YAML y viceversa. Eso ofrece un método muy conveniente de comunicarse con humanos :)
Hay muchos tipos de recursos, y Kubernetes admite la creación de más para uso
interno: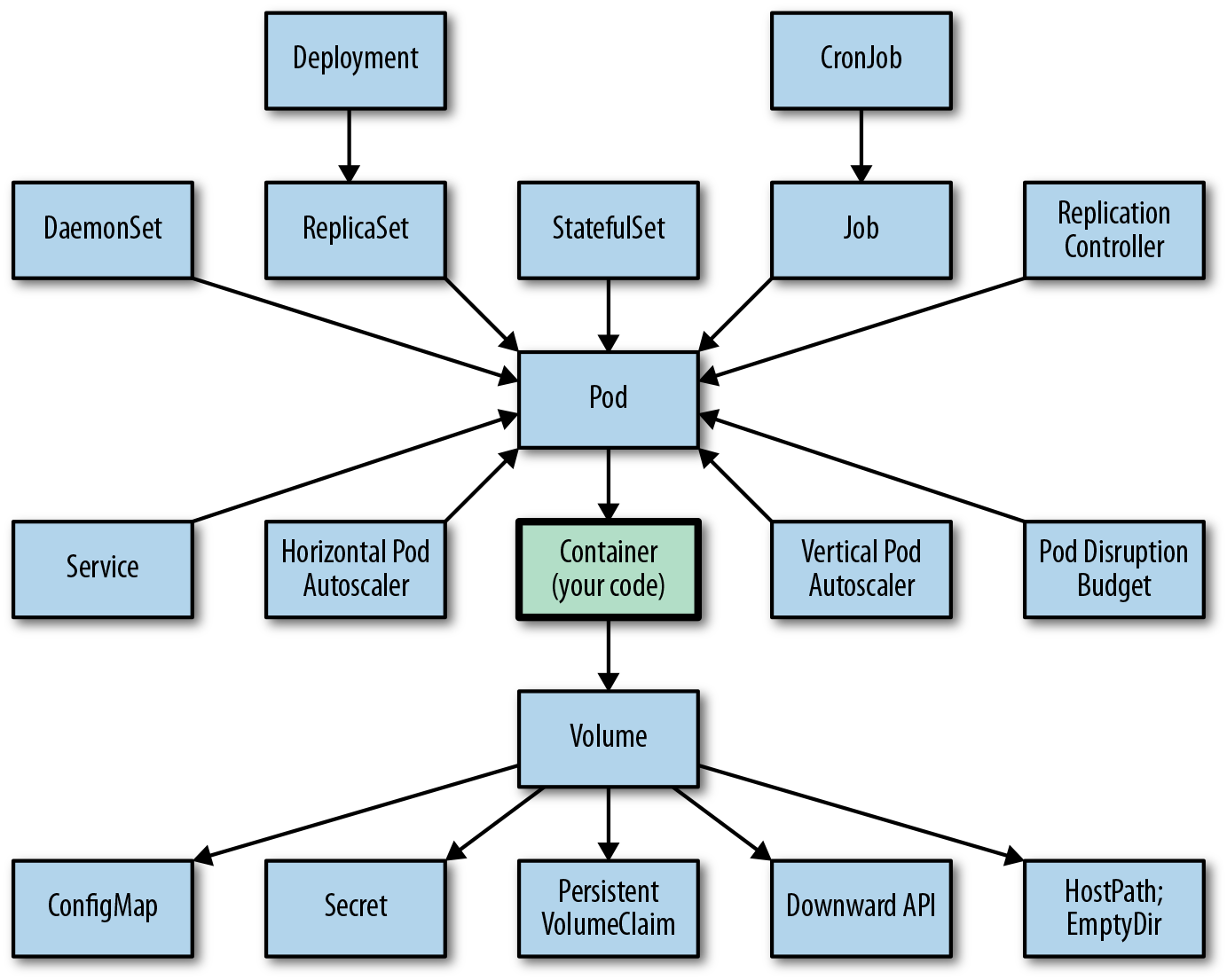
Aquí me voy a centrar solo en los más básicos.
POD
El Pod es fácil de identificar en el gráfico, ya que es donde van todas las flechitas :D. Eso es porque es la unidad mínima de proceso. Dentro tendrá uno o más contenedores, pero si Kubernetes necesita crearlo, destruirlo o reemplazarlo, no se puede cambiar sólo uno de esos contenedores, sino que habrá que gestioar el Pod completo.
Su uso es, justamente, albergar contenedores. Esto incluye puntos de montaje como Secrets o ConfigMaps que veremos un poco más adelante.
Ejemplo:
| |
ReplicaSet
El ReplicaSet es poco útil en sí mismo ya que se suele usar en un nivel superior, los Deployments que vienen justo a continuación.
Se utilizan para gestionar el número de instancias de un Pod, comprobando que haya los justos y necesarios.
Deployment
El Deployment gestiona la creación de ReplicaSets, que a su vez gestionan la creación de Pods. La gracia es que utiliza los ReplicaSets como un historial de estados, permitiendo volver atrás a un “estado” anterior.
Nadie gestiona ReplicaSets a mano… siempre mediante Deployments.
Ejemplo:
| |
DaemonSet
El DaemonSet gestiona la creación de Pods, como los Deployments, pero asegurándose de que haya un Pod por nodo. Si se crea un nodo nuevo, se encarga de crear un Pod nuevo, y si se destruye un nodo, destruirá el Pod.
Son muy útiles para herramientas de monitorización.
Ejemplo:
| |
StatefulSet
Como un Deployment, pero garantizando orden y unicidad de los Pods. Útil para gestionar estados, como lo que necesitan las bases de datos.
Ejemplo:
| |
Job
Un Job es un programa que realiza trabajo. Nace, hace cosas y muere. No se espera que viva eternamente.
Se puede gestionar el paralelismo de los Jobs para evitar solapamientos o gestionarlos
Ejemplo:
| |
Cronjob
Un CronJob crea Jobs de forma temporizada.
Ejemplo:
| |
Service
Al contrario que todos los anteriores, un Service no gestiona Pods, sino que es más bien un proxy que permite acceder a ellos.
El funcionamiento es el siguiente: gestiona una lista de los Pods que tienen
unas labels, ofreciendo un nombre fijo para acceder a ellos, de forma que no
tengamos que referirnos a una instancia concreta (que tendrá un nombre
aleatorio).
Dicho de otro modo: es como un DNS a nivel interno y de grupo de Pods.
Ejemplo:
| |
ConfigMap
Un ConfigMap tampoco gestiona Pods, sino que es un elemento de configuración. Permite guardar claves y valores y montarlos como ficheros o variables de entorno dentro de los Pods.
Ejemplo:
| |
Secrets
Como los ConfigMaps, pero el contenido está codificado en formato base64. Ojo, porque esto no es seguro, ya que cualquiera puede decodificarlo, pero… bueno es “algo” más seguro, ya que es más dificil de recordar y permite guardar binarios.
Ejemplo:
| |
El mismo ejemplo, pero especificado de forma legible para humanos, lo que es válido para crear un Secret, pero no se puede recuperar así:
| |
Los hay de distintos tipos para gestionar distintas cosas: tokens, claves ssl, certificados https, …
Ingress
El Ingress es una puerta al exterior. Abre un Service fuera del cluster de kuberntes. Normalmente están gestionados por un controlador como nginx, kong, …
| |
Saber más
Para saber más… recomiendo jugar con todo lo expuesto aquí. En próximos posts contaré cómo crear un cluster kubernetes desde cero y cómo desplegar algo útil.